In the Weights: a nova busca de vaidade que mede sua relevância dentro das IAs
Thomas Dimson e Joey Flynn criam buscador para medir o peso de nomes próprios nos parâmetros de treinamento de modelos de linguagem como GPT e Claude.
Descubra como a Bayer desenvolveu o PRINCE, plataforma de IA com Agentic RAG e LangGraph para unificar dados e acelerar a pesquisa de fármacos.
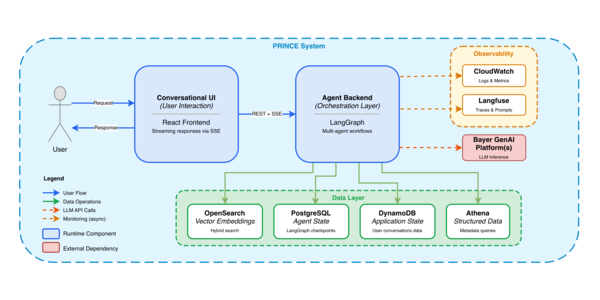
A pesquisa pré-clínica de novos fármacos é, por sua própria natureza, uma das etapas mais complexas, dispendiosas e intensivas em dados de toda a indústria farmacêutica global. Para enfrentar os desafios associados ao acesso eficiente e à análise profunda de volumes monumentais de informações científicas geradas durante essa fase crítica, a gigante farmacêutica alemã Bayer projetou e implementou o PRINCE (Preclinical Information Center). Trata-se de uma plataforma de inteligência artificial de agente único e múltiplo estruturada sobre o paradigma de Agentic RAG (Retrieval-Augmented Generation baseada em agentes). O sistema utiliza uma arquitetura orquestrada por meio do framework LangGraph, alimentada por um backend desenvolvido em FastAPI e disponibilizada aos pesquisadores por meio de uma interface conversacional moderna desenvolvida com a biblioteca React.
O desenvolvimento do PRINCE pela Bayer foi impulsionado pelas limitações históricas dos sistemas tradicionais de busca baseados em palavras-chave e lógica booleana rígida. Na pesquisa pré-clínica, as perguntas científicas formuladas pelos pesquisadores são repletas de nuances conceituais, terminologias sinônimas e contextos biológicos complexos que os mecanismos de busca legados simplesmente não conseguem decifrar. Diante disso, a emergência dos modelos de linguagem de grande porte (LLMs) abriu uma oportunidade para revolucionar o acesso a dados confidenciais e proprietários, combinando o poder gerador dessas redes neurais com a precisão cirúrgica de sistemas modernos de recuperação de informações. Esse esforço resultou em uma plataforma capaz de transformar consultas complexas em linguagem natural em respostas estruturadas, seguras e contextualizadas.
Para compreender a jornada técnica de concepção do PRINCE, é preciso analisar a paisagem de dados que caracteriza a área de pesquisa pré-clínica da Bayer. Como ocorre em grandes organizações farmacêuticas multinacionais, o ecossistema de informações é fragmentado e disperso em múltiplos repositórios e silos internos. O conjunto de dados inclui tabelas altamente estruturadas resultantes de ensaios laboratoriais e, paralelamente, uma massa avassaladora de dados não estruturados contidos em relatórios de estudos em formato PDF, artigos científicos e submissões regulatórias. Esse isolamento de dados impedia que os cientistas obtivessem uma visão holística e consolidada sobre compostos químicos específicos, exigindo um trabalho de compilação manual exaustivo que consumia tempo precioso que poderia ser dedicado a atividades científicas essenciais.
A evolução do PRINCE dentro da Bayer não ocorreu de forma abrupta, mas sim por meio de um planejamento estratégico de desenvolvimento dividido em três fases distintas denominadas Search, Ask e Do. A fase inicial, batizada de Search, concentrou seus esforços na construção de uma porta de entrada única para milhares de relatórios de estudos não clínicos, integrando múltiplos repositórios internos que antes operavam isolados. Nessa etapa primária, a plataforma apoiava-se majoritariamente em metadados estruturados para permitir que os pesquisadores aplicassem filtros avançados sobre as informações de estudos pré-clínicos cadastrados nos sistemas da companhia.
Contudo, uma fração considerável do conhecimento científico pré-clínico acumulado pela Bayer ao longo de décadas reside exclusivamente em relatórios de estudo não estruturados armazenados em formato PDF. Devido a sucessivas migrações de sistemas de TI executadas no decorrer dos anos, os metadados estruturados associados a esses arquivos podiam conter lacunas graves, anotações incorretas ou simplesmente estar ausentes. Os engenheiros de software e cientistas de dados compreenderam que as informações consideradas o "padrão-ouro" de verdade científica estavam contidas estritamente no corpo textual dos relatórios em PDF aprovados. Isso motivou o início da segunda fase do projeto, denominada Ask.
Com a introdução da fase Ask, a plataforma passou por uma quebra de paradigma ao incorporar técnicas avançadas de Retrieval-Augmented Generation (RAG). Essa inovação permitiu que os pesquisadores fizessem perguntas diretamente ao conteúdo interno dos relatórios em PDF, incluindo documentos históricos digitalizados que passaram por processos de reconhecimento de caracteres. Ao invés de preencher formulários de filtros rígidos, os cientistas começaram a interagir diretamente com a inteligência artificial para extrair insights profundos e fazer perguntas conceituais diretamente às fontes originais de dados.
Atualmente, o PRINCE encontra-se em sua terceira fase evolutiva, conhecida como Do. Nessa etapa, o sistema transcende a simples recuperação de dados e atua de maneira proativa como um assistente de pesquisa ativo. Através da implementação de sistemas multiagente integrados, a plataforma é capaz de lidar com requisições altamente complexas, quebrar problemas científicos em subtarefas, orquestrar fluxos de trabalho que exigem chamadas a múltiplas ferramentas e realizar tarefas avançadas, como a redação preliminar de rascunhos de documentos científicos para agências regulatórias internacionais.
O desenvolvimento de um sistema baseado em inteligência artificial para o setor de saúde exige níveis extremos de confiabilidade e rastreabilidade de dados. Na arquitetura do PRINCE, a equipe da Bayer adotou princípios rígidos de engenharia de contexto (context engineering). Embora esse termo não fizesse parte do vocabulário inicial de design, ele descreve perfeitamente o rigor aplicado à movimentação e filtragem das informações que são expostas a cada modelo de linguagem (LLM). O time técnico identificou precocemente que janelas de contexto gigantescas oferecidas pelas LLMs modernas não eliminavam a necessidade de seleção cirúrgica de dados.
Em versões iniciais de teste do sistema, a tentativa de inserir um volume excessivo de informações misturadas no mesmo prompt de sistema resultou em grandes dificuldades de guiar o comportamento do modelo e de avaliar suas saídas de maneira padronizada. O excesso de dados irrelevantes gerava o fenômeno de poluição de contexto, prejudicando o desempenho do modelo na tomada de decisões. Para solucionar esse problema, o PRINCE foi estruturado de forma que cada etapa da orquestração receba apenas a fração exata de contexto necessária para sua execução específica. O contexto de planejamento é reservado para a fase de pensamento, o contexto de recuperação é direcionado ao agente pesquisador, o contexto de evidências é entregue ao agente de reflexão, e apenas a síntese depurada é exposta ao agente redator.
"Muitas das decisões de engenharia por trás do PRINCE podem agora ser compreendidas através das lentes da engenharia de contexto e da engenharia de suporte, embora quando o sistema foi originalmente projetado nós não utilizássemos esses termos."
Se a engenharia de contexto cuida da qualidade da informação consumida pelos modelos de inteligência artificial, a engenharia de suporte (harness engineering) é a disciplina encarregada de erguer as estruturas de proteção e infraestrutura de software ao redor do sistema PRINCE. A engenharia de suporte na Bayer envolveu o gerenciamento detalhado da orquestração dos agentes, definição estrita de fronteiras para o uso de ferramentas externas, persistência de estados do sistema, definição de políticas inteligentes de retentativas de requisição, rotas de contingência e fallback, validação contínua de respostas e inserção de laços de revisão humana.
Toda essa engenharia de suporte permitiu que o sistema atingisse níveis de resiliência corporativa aptos para lidar com dados científicos confidenciais. A evolução desse arcabouço tecnológico e a validação de seus resultados na produtividade diária dos cientistas foi documentada em detalhes em um artigo científico revisado por pares e publicado na renomada revista de divulgação científica Frontiers in Artificial Intelligence. O artigo aborda a evolução do produto e detalha o impacto de negócios gerado na aceleração das atividades pré-clínicas da Bayer.
A recuperação de informações no backend do PRINCE apoia-se sobre um ecossistema de dados distribuído e otimizado para lidar com formatos estruturados e não estruturados de maneira unificada. Para processar buscas semânticas em documentos textuais e PDFs de relatórios históricos, o sistema armazena representações vetoriais densas desses arquivos em uma base de dados indexada pelo OpenSearch. Essa tecnologia atua como o principal motor de busca do pipeline de RAG, localizando trechos específicos de documentos científicos que contenham as respostas para as perguntas formuladas pelos usuários finais.
Para além dos dados textuais não estruturados, a pesquisa pré-clínica gera registros numéricos estruturados que descrevem ensaios de compostos e metadados de estudos. Esses dados, refinados por processos constantes de carga e harmonização de dados (ETL), são mantidos em ambientes analíticos de nuvem. Os agentes de inteligência artificial do PRINCE interagem com essa base de dados estruturada gerando comandos estruturados de consulta e executando-os por meio do serviço Amazon Athena, o que assegura precisão absoluta no processamento de consultas quantitativas.
Para assegurar a estabilidade do fluxo de trabalho e rastrear a execução de cada decisão tomada pelos agentes de inteligência artificial, o backend gerencia dois tipos de persistência de estado. O estado interno de execução do grafo multiagente, controlado pelo LangGraph, é persistido após cada passo ou nó lógico de execução diretamente em uma base de dados relacional PostgreSQL, fazendo uso de adaptadores de verificação (checkpointers) integrados ao framework de orquestração. Adicionalmente, as informações gerais da aplicação em nível global de sessão de usuário são persistidas de forma escalável e segura nas tabelas do banco de dados não relacional Amazon DynamoDB.
A arquitetura de processamento cognitivo do PRINCE foi desenhada de modo a não ficar dependente de um único fabricante ou provedor de inteligência artificial. A plataforma utiliza a infraestrutura unificada da Bayer de serviços generativos de nuvem corporativa. Esse ambiente corporativo hospeda modelos de linguagem líderes de mercado desenvolvidos pela OpenAI, pela Anthropic e pelo Google, além de disponibilizar diversos modelos de código aberto mantidos localmente na infraestrutura interna da companhia.
O acesso a esses modelos por parte dos agentes de processamento de linguagem do PRINCE é padronizado através de um barramento de API único, que expõe uma interface de comunicação compatível com os padrões de desenvolvimento da OpenAI. Essa abstração técnica reduz custos de desenvolvimento, permitindo que os engenheiros realizem substituições rápidas de modelos (model swapping) de acordo com o nível de complexidade de cada tarefa do grafo. Tarefas mais triviais de conversão ou formatação podem rodar em modelos menores e de menor custo de computação, ao passo que tarefas analíticas complexas que exigem forte raciocínio lógico são direcionadas para os modelos de maior porte dos provedores parceiros.
Essa plataforma unificada atua ainda como o plano de controle administrativo centralizado da Bayer para ferramentas de inteligência artificial generativa. É por meio dessa camada que a empresa impõe políticas de restrição de tráfego, limites de consumo (rate limits) e regras rígidas de segurança corporativa para prevenir abusos operacionais ou uso indevido de recursos em nuvem, garantindo total conformidade técnica e financeira com os orçamentos globais de TI definidos pela companhia.
Em sistemas tradicionais baseados em chamadas diretas de APIs, instabilidades de conexão ou respostas inválidas de servidores externos costumam causar erros críticos que interrompem a experiência do usuário. Para evitar esse comportamento destrutivo no PRINCE, a equipe de engenharia projetou uma robusta malha de tratamento de falhas. Caso um modelo de linguagem falhe ao processar uma requisição, o sistema intercepta o erro e dispara imediatamente uma série de tentativas automáticas de repetição. Se a falha persistir por múltiplas tentativas, o sistema ativa uma rota de fallback e direciona a requisição para um modelo alternativo hospedado em outro provedor.
As repetições de tentativas são tratadas de forma granular no PRINCE, operando tanto na camada elementar de chamadas a APIs de LLMs individuais quanto na camada de nós lógicos do grafo de orquestração do LangGraph. O aspecto diferencial dessa arquitetura reside no fato de que os agentes que compõem o sistema são alimentados com o contexto técnico detalhado dos erros gerados durante as tentativas frustradas. Isso significa que, se um agente pesquisador gerar uma consulta SQL incorreta que cause erro de sintaxe no Amazon Athena, ele lerá o log de erro retornado pela base de dados e de forma autônoma recalculará sua rota, reescrevendo a consulta até obter um retorno válido para o usuário.
O fluxo de orquestração do PRINCE baseia-se em um grafo direcionado coordenado pelo framework LangGraph. O primeiro passo desse fluxo é a etapa de Clarify User Intent (Esclarecimento de Intenção do Usuário), que atua como uma barreira inicial contra a ambiguidade. Na pesquisa pré-clínica de novos fármacos, os termos científicos podem possuir significados distintos de acordo com a área de estudo. Uma consulta curta e vaga sobre dosagem pode gerar caminhos completamente diferentes se interpretada sob a ótica da toxicology (toxicologia) ou da pharmacology (farmacologia). Para evitar o acionamento de pesquisas dispendiosas em bancos errados, o sistema interage com o pesquisador apresentando perguntas esclarecedoras rápidas para delimitar o escopo antes de consultar as bases de dados.
Uma vez esclarecida a intenção científica da consulta do usuário, o controle de execução passa para o nó Think & Plan (Pensar e Planejar). Esse componente avalia a requisição final e desenvolve um plano de ação estruturado, determinando quais bases de dados e ferramentas devem ser consultadas para obter a resposta exata. Em seguida, o plano é enviado para os agentes executores especializados da plataforma. O principal deles é o Researcher Agent (Agente Pesquisador), cujas ferramentas de busca semântica em formato vetorial localizam documentos no OpenSearch e cujas capacidades de geração de código SQL extraem dados consolidados do Amazon Athena.
Depois de coletadas as informações brutas, o fluxo de dados atinge o Reflection Agent (Agente de Reflexão), cuja responsabilidade primária é analisar e validar a completude e a consistência das evidências localizadas. Se o agente de reflexão detectar incoerências de dados ou lacunas de informações essenciais, ele reinicia o fluxo de busca de forma automatizada, notificando o agente pesquisador sobre as lacunas identificadas. Somente após a validação completa das evidências coletadas, o fluxo avança para o Writer Agent (Agente Redator), encarregado de condensar os insights científicos de forma clara e estruturar a resposta final em linguagem natural de volta para a interface de usuário construída em React.
Para assegurar que o sistema opere com máxima precisão e segurança e que possíveis instabilidades de comportamento ou alucinações de dados sejam interceptadas antes de causar problemas de pesquisa aos cientistas, a Bayer construiu uma malha abrangente de observabilidade e validação contínua. As métricas tradicionais de integridade de servidores, tempos de resposta HTTP e uso de memória são monitoradas em tempo real utilizando as ferramentas nativas de infraestrutura do Amazon CloudWatch.
As métricas específicas de comportamento dos agentes generativos, por sua vez, são registradas em nível detalhado de transação por meio do framework de observabilidade de LLMs Langfuse. Através do Langfuse, os engenheiros de software têm acesso a traces de execução pormenorizados, sendo capazes de inspecionar individualmente a entrada e a saída de cada chamada efetuada ao longo do grafo multiagente, facilitando o diagnóstico de erros de execução lógica de prompts de sistema.
A avaliação contínua da qualidade de respostas da arquitetura de RAG no PRINCE baseia-se no framework automatizado de avaliação RAGAS (Retrieval Augmented Generation Assessment). Esse conjunto de métricas permite estimar a relevância da resposta final face ao contexto original recuperado e estimar o grau de fidelidade das informações apresentadas frente ao conteúdo verídico das fontes científicas. A Bayer realiza testes de validação contínua diariamente sobre o tráfego em tempo real registrado nas plataformas de produção. Adicionalmente, avaliações amplas baseadas em conjuntos de dados de testes são executadas de forma automatizada todas as vezes que modificações são aplicadas nos prompts dos agentes, na lógica de orquestração do LangGraph ou quando novos modelos de linguagem são homologados pela equipe técnica da plataforma.
Thomas Dimson e Joey Flynn criam buscador para medir o peso de nomes próprios nos parâmetros de treinamento de modelos de linguagem como GPT e Claude.
O vencedor do Nobel de Química John Jumper deixa o Google DeepMind para se juntar à Anthropic, redefinindo o mercado global e a disputa por talentos em IA.
Com auditoria independente da Appen, a startup Subquadratic apresenta o SubQ, modelo que promete processamento 56 vezes mais rápido com custo reduzido.